网络概论扫盲笔记。
数码网络的运作:
将要传输的数据拆碎成适当大小的区块,每个区块叫做数据包(packet),每个数据包有个首部(header)会写上接收方的地址,要传输的数据本身称为酬载(payload),然后再通过网络来传输
网络传输协议:
就是指数据包首部的格式,要规范这个格式,才可以顺利地将数据包发送出去,告诉中间传输的网络设备,让它知道要寄到哪里去。
网络分层设计:
实务被分为四层:
| 层 | 定义 |
|---|---|
| 数据链路层link layer | 用来处理局部网中硬件连接的传输,例如Etherent协议,无线网络802.11n协议,3G/4G手机网络 |
| 网络层internet layer | 用来处理因特网中的网络设备和网络设备之间的传输,例如IP协议 |
| 传输层Transport layer | 用来处理电脑到电脑之间的可靠传输,例如TCP,UDP协议 |
| 应用层Application layer | 网络应用程序之间如何处理数据,例如HTTP协议 |
可以将分层想象成数据包了四个信封,一层包一层,HTML数据是最里面的酬载(payload),被包在HTTP里面,外面再包上TCP,IP,最后再包一层Etherent。
| Etherent首部 | IP首部 | TCP首部 | HTTP首部 | 实际的数据HTML |
分层设计的好处:
灵活性高,可扩充性好。当某一层需要改变的时候,只需要替换那一层就好了。而且层次化后,设计新协议也会简单很多,而不需要每次都重新设计全部的协议。
数据链路层link layer
电脑上网需要连接网线或者用无线网络,来连接到路由器,这之间就需要一层信封写上地址,以告诉路由器把数据传回来的时候,送到哪一台电脑上。
这一层的传输协议根据硬件连接方式的不同而有不同的协议,常见的有:
- 有线网络使用以太网协议(Ethernet)
- 无线网络的 IEEE802.1协议
- 移动通信网络使用3G,4G协议
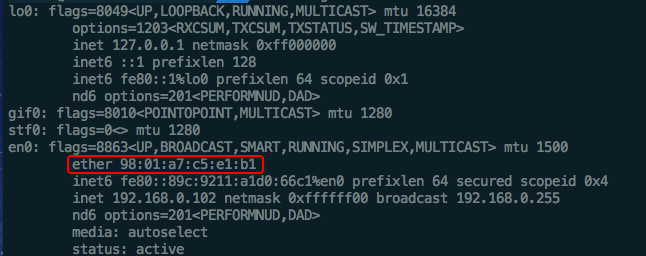
每个网络设备在出厂时,都配有一个Mac地址(Media Access Control Address)。这个地址将用于直接相连在一起的硬件。例如多台电脑连接了一个路由器,那么路由器就会用Mac地址决定数据包要寄到哪里去。
终端输入ifconfig可以看到Mac地址:
传输路径是这样的:
当你需要将数据传输到公开的网站时,首先会从你的电脑传到路由器,信封会填上路由器的Mac地址,然后发送出去,路由器收到后,会把这一层信封拆掉,换上与路由器直接连接的ISP路由器的Mac地址,然后寄到下一个网络设备,以此类推直到目的地网站服务器。
ISP:internet Service Provider,互联网服务供应商,指的是例如中国移动,中国联通的因特网电信运营商
网络层Internet Link
数据链路层使用的Mac地址,还有直接相连网络设备才会知道。你的电脑知道路由器的Mac地址,路由器知道与它相连接的ISP设备的Mac地址,但我们并不知道路由器出去之后的网络设备的Mac地址。
数据包packet由一个路由器传递给下一个路由器,每个传递都更接近目的地,而这个目的地需要一个地址,这就是IP协议所处理的。第四版IPv4由4bytes的数字组成,形式是XXX.XXX.XXX.XXX.
IP地址是全球唯一的,最多可有42亿多个,但随着互联网的大量普及,已经与2011年2月全部分配完毕。新的标准IPv6使用了16bytes来表示网络位置,不过实务上对一般用户似乎很少用到。这是因为要使用IPv6,必须客户端到服务器中间的网络设备都要支援IPv6,而大部分的ISP营运商都还没有默认支援IPv6.
IP地址在设计时,保留了一些私有IP地址用于局域网,最常见的是192.168.0.0~`192.168.255.255这个范围。你连上无线路由器时,都会被分配到这个地址。另外还保留了127.0.0.1` 代表的是本机电脑,私有IP地址。
CIDR块:
CIDR是一种IP地址的表示法,全称Classless Inter-Domain Routing无类别域间路由,用来表示一整个区块的IP位置。
例如:
a.b.c.0/16的意思是a.b.0.0到a.b.255.255,共 65,536 个地址
NAT技术:
IPv4已经分配完毕,但是大家并不很着急要升级到IPv6,为什么呢?因为NAT技术,因此不需要每一台上网的电脑,都需要一个公开的IP地址。
透过NAT技术,只有路由器那一台网络设备需要公开的IP地址,局域网内使用私有IP地址即可。路由器会记得当初数据包是从哪一台电脑送出去的,当数据包从因特网返回时,会做一个IP地址转换。
但是如果一台电脑是因特网上可以被连线的服务器,必须要有一个公开的IP地址。
DHCP协议:
当电脑连上路由器时,会自动请路由器分配一个局域网的私有IP地址给你。通常的范围在
192.168.1.1到192.168.1.255之间
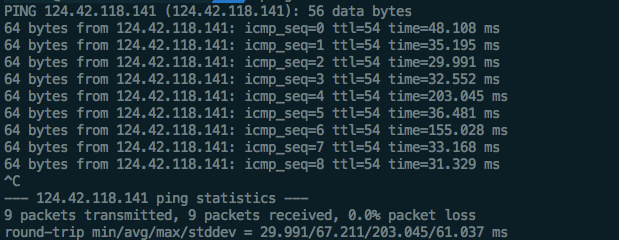
Ping指令:
ping用来测试数据包送到目的地所需要的时间,其中time是往返时间,这个时间主要取决于地理位置。如果你去ping台湾或日本的服务器大概需要50ms,去ping美国的要200ms,要去欧洲或者南美洲那就更远了。这也是为什么网站的连线速度要好,就得把服务器摆的离用户比较近的原因。
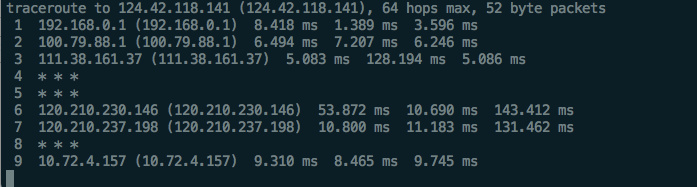
traceroute指令:
用来追踪到达目的地过程中,每台路由器节点的回应:
ping和traceroute一样,不是每台路由器都会回应这个信息,有些路由器会关闭这个功能。
传输层Transport layer
IP数据包抵达对方电脑后,要给哪个程序去处理呢?这时候就要用到传输层协议。
在传输层TCP,UDP中定义了Port Number,在数据包首部写上来源埠(source port number)和目的埠(destination port number),不同的应用程序会用不同的Port,每一个需要用到网络的程序,都必须跟操作系统登记申请一个Port来使用,操作系统会去确认说一个Port只能分给一个程序使用。
IP协议让我们可以将数据包从因特网的一端传送到另一端,但是没有保证数据包的可靠传输。传输过程中,可能被中间的路由器丢失,不同数据包也可能因为经过不同路由器而造成抵达的顺序不同。
因此在TCP协议中实做了更多步骤来保证资料传输的正确性,包括会重发遗失的封包,舍弃重复的封包,无错误资料传输,阻塞/流量控制,确认建立三方交握,连线已建立才做传输等等算法。
TCP是非常复杂的协议,也是使用最为广泛的协议,和IP协议合称TCP/IP,大部分的应用层协议,包括HTTP,都是基于TCP/IP的。
应用层Application Layer
TCP/IP协议是操作系统就会提供的网络功能,而在我们电脑上会有不同的应用软件,这些软件基于TCP/IP实作应用层协议,例如:
- DNS
- HTTP
- SSH
- FTP档案传输
- SMTP寄email
- POP收email
- SMB微软的网络文件共享系统
- ……
其中,最常见的是DNS协议和浏览器使用的HTTP协议。
DNS
由于IP地址不好记忆,所以我们偏好让用户使用域名来访问服务器,但是数据包要传递必须使用IP地址,因此,域名系统便用来做Domain Name和IP地址的转换。
DNS机制基本上就是一个对照表,对照某某域名的iP地址是什么。
本地便有一个对照表档案,见/etc/hosts.
域名:
一个网域名称组成是
sub-domain.second-level-domain(your-domain).top-level-domain.
- 全世界的top-level-domain由互联网号码分配局IANA机构所管理,每个top-level-domain会分配给不同国家的非营利组织进行管理。所有的top-level-domain列表请参考Root Zone Database。
- 一般个人或者公司组织会向这些非营利机构组织进行网域购买和登记。在一些域名注册商Name cheap, Godaddy, 阿里云-万网的网站上,可以一次选购各种不同的网域。
DNS是如何查询的?
一般用户如何进行DNS查询呢?通常是使用ISP默认提供的DNS服务器,也可以自己指定,例如:
- 阿里DNS http://www.alidns.com
- 国内114dns的114.114.114.114
- google的8.8.8.8
可以在你的Mac中设定DNS Servers为Google的8.8.8.8。
查询流程是先从客户端偏好的DNS开始,如果找不到,则该DNS会从根网域名城服务器开始查询,直到找到负责该网域的DNS服务器为止。在第一次查询后,客户端偏好的DNS就会被缓存起来。
nslookup指令:
可以简单查询DNS
终端输入:
nslookup {domain-name}输出的address就是IP
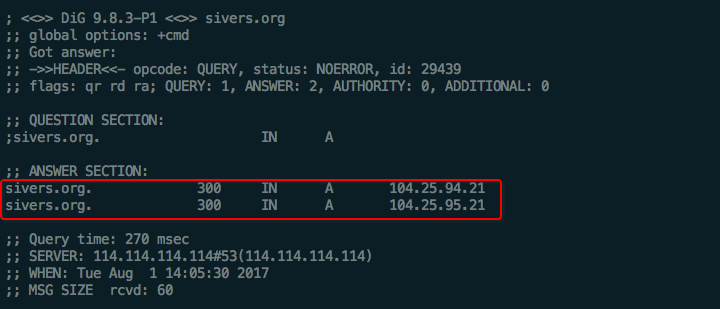
dig指令:
也可以查询DNS,提供更为详细的数据:
例如:
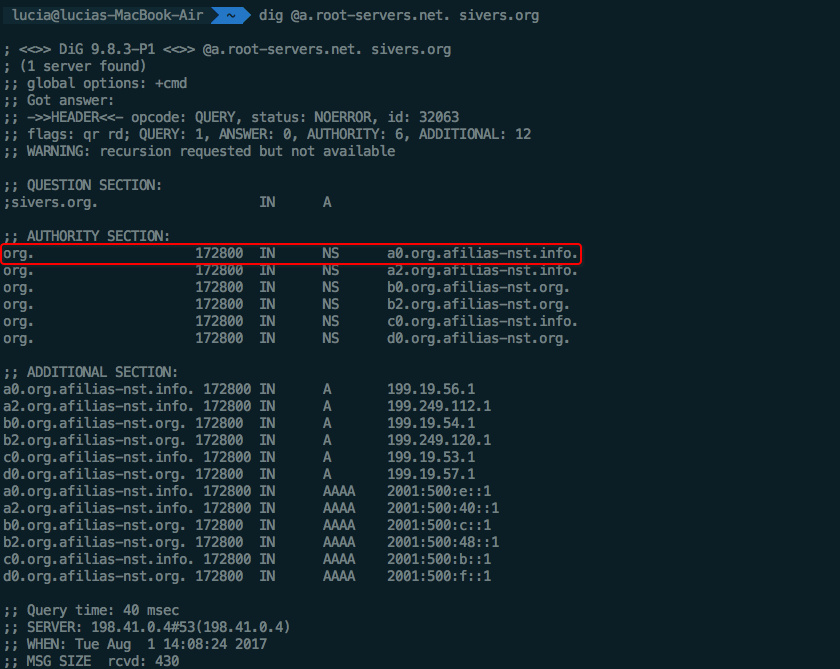
dig sivers.org得到如下结果:
也可以从根网域服务器开始查询:
不敲代码了,上图:
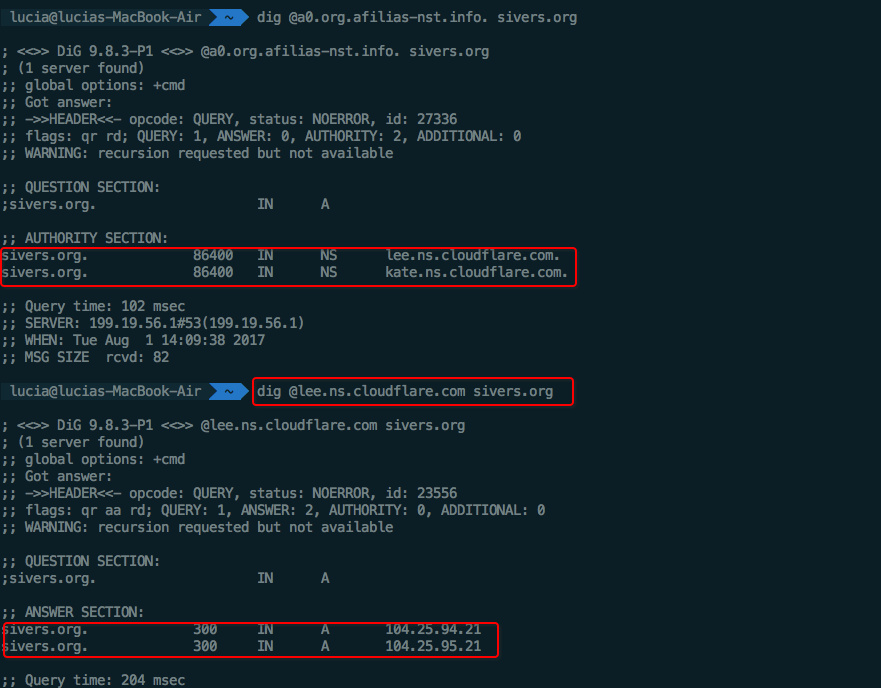
DNS纪录有分不同类型,例如:
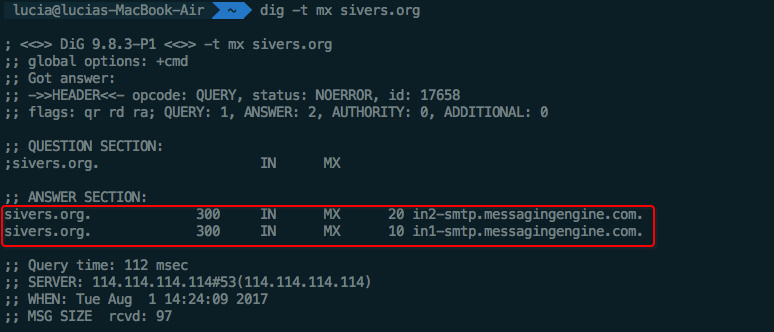
A一笔IPv4纪录,某个subdomain指向某一个IPv4地址AAAA一笔IPv6纪录MX邮件服务器CNAME别名,可以设定某个subdomain指向另一个地址查看MX纪录:
DNS使用情境:
- 标售哄抬现象: 因为购买单个网域一年并不贵,所以一些热门的网址组合,很多网络蟑螂会预先注册保留起来,如果要买则需要花更贵的价钱才能买到。当然,也可走法律程序,但不容易处理。
- 故障排除:有时候网络好像故障了,浏览器无法连接,但是可以用
ping {ip-address}, 这时候可以优先检查是否是DNS坏了,换一台试试。【经历过一次,还以为是翻墙的原因,后来求助得到解答,换了DNS,比如换成114.114.114.114或者8.8.8.8】 - 钓鱼网站:所谓的钓鱼网站,是利用网址很像,然后画面弄成一样骗你输入账号秘密。
- 网域忘记续约:购买网域是需要定期续约的,一年,三年,五年等,在大公司可能因为交接失败,造成网域实效的现象层出不穷。
- Geo-based或Round-Robin:查询DNS时,不一定总是回答同一个IP答案,有些网站在不同国家都有服务器,但是希望网址一样的,这时可以根据用户不同的地理位置,回答不同的IP答案。
- DNS污染:在一个理想信任的网络环境中,如果用户的DNS不知道答案,它会一层层去询问,但是在一个受管制的网络环境,DNS可以被控制回答不正确的IP位址,进而限制一般用户无法顺利浏览,甚至回答钓鱼网站的IP,这种行为叫做DNS污染。
HTTP
HTTP:Hypertext Transfer Protocol(超文本传输协议),是由客户端发送HTTP request 请求到服务器端,然后服务器端返回HTTP response回复。
HTTP一定先从客户端开始,服务器端不能直接发送信息给客户端。
加餐:Internet与Web的技术差别是?
用TCP/IP技术的是internet,用HTTP的是Web。万维网也是因特网的一种,但不是每一个internet的应用都使用HTTP,例如email用的是SMTP协议。
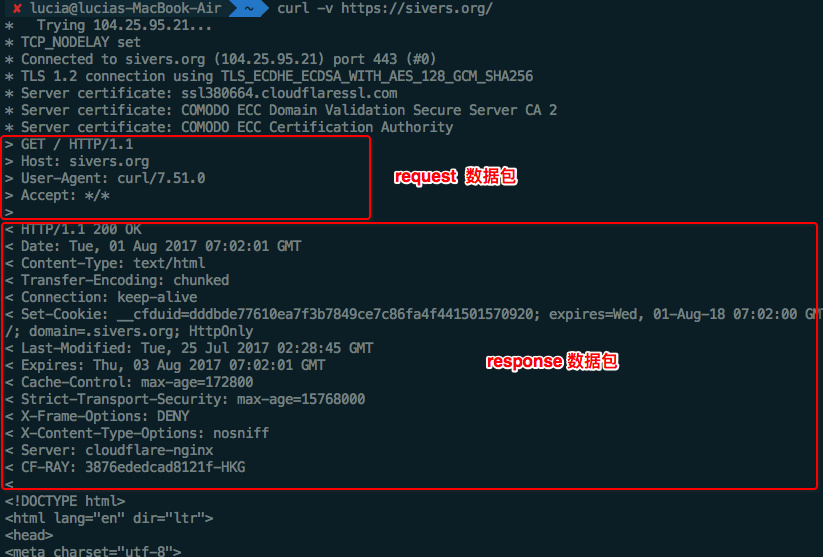
Curl工具:
curl 指令可以在命令行中发送HTTP Request。如下:
浏览器的HTTP工具:
浏览器Inspector
使用Google chrome的inspector可以观察HTTP Networking的情形:
你会发现浏览器要完整加载一个网页,必须要发送非常多的request。第一个request拿HTML,接着浏览器会解析HTML内容,找出还需要哪些CSS/JavaScript和图档等资料,然后再发送HTTP Request去抓取这些资料。
浏览器Extension
进入chrome选单的extension,可以安装postman等扩展程序
HTTP数据包:Request Response
HTTP Request
一个HTTP Request包括几个部分:
- HTTP方法
- 网址,包括URL+ parameters
- HTTP首部headers
- 信息内容Message Body,GET方法没有这个部分
HTTP方法常见的有以下几种:
- GET:安全且幂等,用来读取数据
- POST:不安全且不幂等,用来新增数据或执行某个操作
- PUT:不安全且幂等,用来置换数据
- PATCH:不安全且不是幂等,用来修改数据
- DELETE:不安全但幂等,用来删除数据
这里,安全和幂等的意思如下:
安全:这个操作不会修改到服务器的数据,但这是语意上的意思,不代表服务器的实作。例如GET某一个网站,服务器还是可以实作浏览量功能。
另外互联网都会假设GET是可以重复读取并缓存的,而POST不行,因此搜索引擎只会用GET抓取资料。
幂等:如果相同的操作再执行第二遍第三遍,结果还是跟第一遍的结果一样,也就是不管执行多少次,结果都跟只执行一次一样。
HTTP首部
常见的Request Header,例如:
> Host: sivers.org
> User-Agent: curl/7.51.0
> Accept: */*
- Host 指的是请求的网域名称;
- User-Agent 是用户使用的软件
- Accept是指希望服务器回传的格式。
*/*是都可以的意思。
信息内容:
GET没有信息内容,要用POST/PATCH/PUT/DELETE才会有信息内容。
HTTP Response
一个Response包括几个部分:
- 状态码(response status)
- 首部(response headers)
- 信息内容(response body)
例如:
HTTP/1.1 200 OK
Content-Type: text/html
<html>
<h1>这是HTML源码</h1>
<p>....</p>
</html>
这里HTTP/1.1是HTTP规格的版本,200是状态码数字,OK是状态码。
Content-Type: text/html 是首部部分;
后面则是信息内容。
了解完整的HTTP状态码:HTTP 状态码列表
HTTP的无状态特性:
每个Request之间都是完全独立的,也就是说每个request必须带有完整的参数来完成操作。
那如何识别登入的用户?
每个Request都自带可以识别的资讯,例如浏览器会使用cookies这个功能。服务器透过Response Header的Set-Cookie来告诉浏览器要记住一些数据,然后浏览器就会在之后的Request都带有Cookie这个header。
另外Cookie只会向同一个网域送出,基于浏览器的安全同源政策(same-origin policy)
URL
以http://www.example.com/home为例:
- 协议用http
- 服务器主机Host是
www.example.com - URL路径是
/home - Port号码:http默认是80,https默认是443
什么是Query strings/Parameters?
可以用来额外传递一些参数给服务器,例如
https://www.google.com.hk/search?search=ruby&results=10GET, POST都可以用Query strings的写法来传递参数,但GET比较常见,因为GET没有body,只能用这种方式来传参数给服务器。
此外:
- Query Strings有长度限制
- 不适合传敏感信息
- 空白和特殊字符必须做出逸出编码,编码规则详见:URL Encoding
什么是HTTPS和HTTP/2?
HTTPS: 没有加密的HTTP连线,可以透过监听网络封包,知道浏览器传输的内容,而HTTPS可以简单理解为加密了【我是这么理解的:P】
HTTP/2: 2015年制定的最新HTTP标准,语意和功能都与HTTP1.1相容。
浏览器的 Request/Response Lifecycle
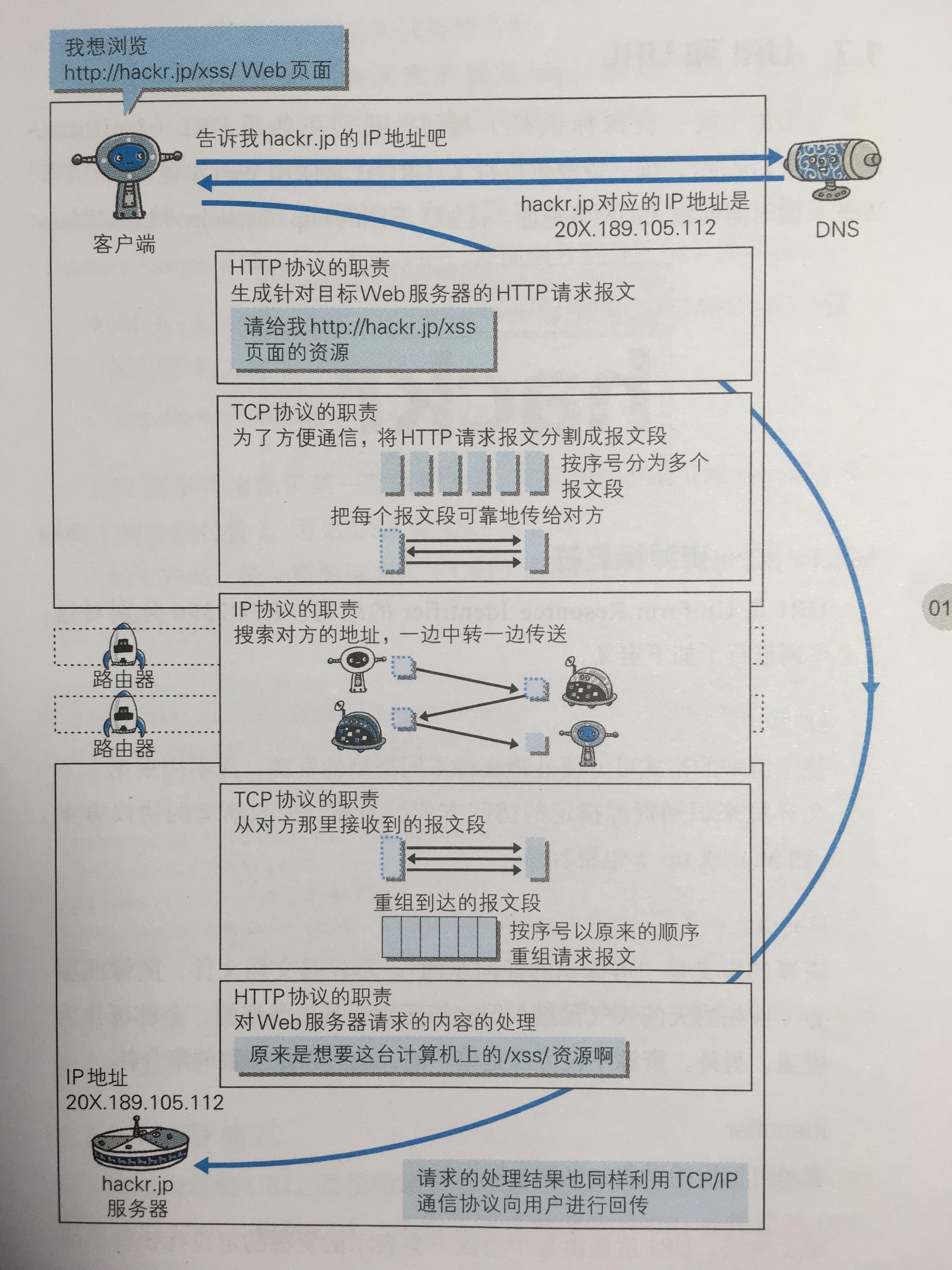
看完了这些多,我的理解是:
当我们在网页浏览器的地址栏中输入一个网址后,浏览器会对这个网址进行解析,分解出protocol,host,port,path,然后DNS会根据host将网址转化成IP地址,生成IP数据包,TCP将这个数据包拆分成多个大小在1.4KB的小数据包,浏览器发送请求,然后电脑将Mac地址传给路由器,路由器根据接收到的这个Mac地址,换上ISP的Mac地址,然后将数据包传送给下一个路由器,数据包在多个路由器之间进行传送,每次传送都会离目的地更近一些,这些数据包到达目的地后,根据TCP协议,进行重新组装,然后服务器根据数据包中的HTTP request 内容给到相应的response,并将response回传给到浏览器,浏览器根据回传到的response信息,进行解析,生成网页。