做cucumber测试时,使用capybara来截取整个网页,掉进了一个坑,记录下,也附上最终的解决方法。
正文
默认情况下,capybara截取的图片大小尺寸是由自己设置的window.size来决定的,如果你想截取全屏怎么办?
这样的需求肯定不是你第一个提出来,所以Google下, how to get full page screenshot with capybara ,会得到一些相关的链接,比如这条:
Is it possible to take a screenshot of the whole page with Selenium/Capybara?
看解答,很简单,窃喜,这么快就解决了:
page.save_screenshot('screen.png', full: true)
连提问者本人都对这个解答很满意,亲测有效,立马试试。
然后你会发现,根本没有任何效果,截取的仍然不是整个网页,只是一部分页面,这时候,可以去看源码Capybara::Session#save_screenshot, 发现确实有option的选项:
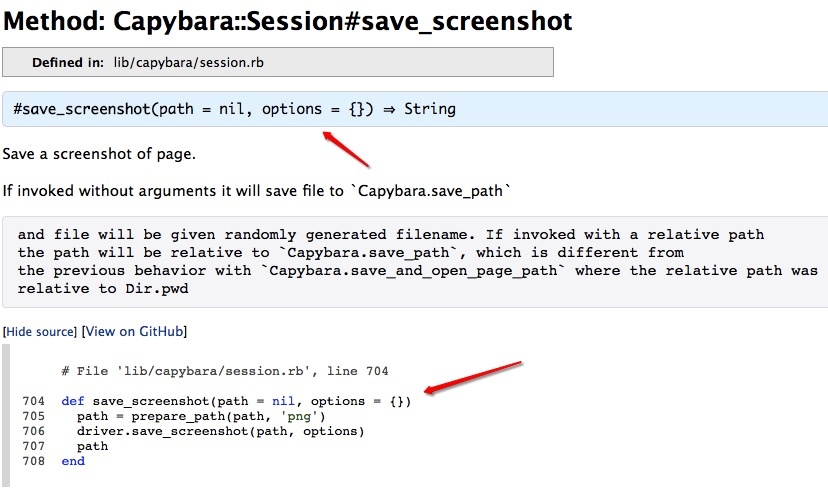
这样看,应该没错啊,然后你会怀疑是不是自己代码敲错了,符号敲的不对,还是哪里没有设置好……
这个地方真的是个坑。
为什么坑?因为你没注意看这个解答中提到的driver是Selenium,而它通常的搭档browser是Firefox, 不是chrome,所以只能说是你的粗心给自个挖了个坑……
这里,你会想问,为什么是headerless_chrome时就不行了呢?
还是stack overflow:【强大的stack!】
看这个save_screenshot(path, full: true) is not capturing the full browser?
这里,Thomas Walpole的解答非常清楚,忍不住想点赞。【可惜我的reputations还不到15……】

查看selenium的takes_screenshot, save_screenshot的定义中,参数只有一个path:
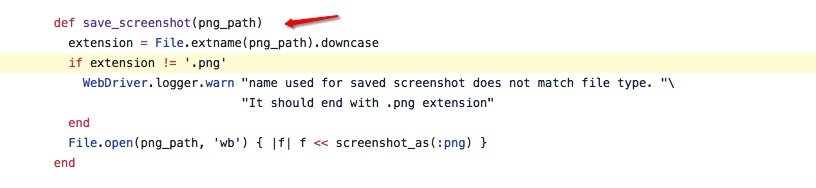
所以,剩下的就简单了,去resize window即可。
好,不废话了,直接上货:
在features/support下新建文件screenshot.rb, 放入以下内容:
def full_page_screenshot(file_name = nil)
width = Capybara.page.execute_script("return Math.max(document.body.scrollWidth, document.body.offsetWidth);")
height = Capybara.page.execute_script("return Math.max(document.body.scrollHeight, document.body.offsetHeight);")
window = Capybara.current_session.driver.browser.manage.window
window.resize_to(width, height)
file = Capybara.page.save_screenshot(file_name)
return file
end
上图看清楚点:

这里,width,height是调用脚本来运行得到的,也就是借助JS获取了当前打开页面的长宽值。
参数方面,file_name我用了nil作为默认值,这样更灵活,既可以用capybara默认生成的文件名,也可以自定义。
调用的时候,直接调用full_page_screenshot就好了。
上个效果图:【截取了codepen主页】
参考
Full page screenshot with selenium
save_screenshot(path, full: true) is not capturing the full browser?
How to get window size, resize or maximize window using Selenium WebDriver