写一写Rails中一些常用的查询。
group
等同与SQL中的group_by,使用:
Student.group(:gender).count
即:
SELECT COUNT (*) AS count_all, gender
FROM "students" GROUP BY gender
join
School 与Clazz是一对多的关系。
Clazz.joins(:school)
对应的SQL:
SELECT "clazzes".* FROM "clazzes" INNER JOIN "schools" ON "schools"."id"="clazzes"."school_id"
同样:
School.joins(:clazzes)
对应的SQL:
SELECT "schools".* FROM "schools" INNER JOIN "clazzes" ON "clazzes"."school_id"="schools"."id"
这里joins的参数的单复数很重要,School 与Clazz是一对多的关系,Clazz.joins(:school),school必须是单数,School.joins(:clazzes)时,clazzes则是复数,即参数对应的不是表名,而是association names。
多对多的joins, 比如找出hello老师所在的所有班级:
Clazz.joins(:teachers).where(teachers: { name: "hello" })
对应的SQL:
SELECT "clazzes".* FROM "clazzes" INNER JOIN "teachers" ON "teachers"."clazz_id" = "clazzes"."id"
SELECT "clazzes".* FROM "clazzes" INNER JOIN "teacherships" ON "teacherships"."clazz_id" = "clazzes"."id" INNER JOIN "teachers" ON "teachers"."id" = "teacherships"."teacher_id" WHERE "teachers"."name"="hello"
多表连接查询,比如查找 1班 A组的老师:
Teacher.joins(:clazzes, :groups).where(clazzes: { name: "1班" }, groups: { name: "A组" })
对应的SQL:
SELECT "teachers".* FROM "teachers"
INNER JOIN "teacherships" ON "teacherships"."teacher_id" = "teachers"."id"
INNER JOIN "clazzes" ON "clazzes"."id" = "teacherships"."clazz_id"
INNER JOIN "groups" ON "groups"."teacher_id" = "teachers"."id"
WHERE "clazzes"."name" = "1班" AND "groups"."name" = "A组"
嵌套连接nested joins, 比如找出第一中学1班 A组的老师:
Teacher.joins( :groups, clazzes: [:school]).where(clazzes: { name: "1班" }, groups: { name: "A组" },schools: { name: "第一中学" })
对应的SQL:
SELECT "teachers".* FROM "teachers"
INNER JOIN "groups" ON "teachers".id = "groups"."teacher_id"
INNER JOIN "teacherships" ON "teacherships"."teacher_id" = "teachers"."id"
INNER JOIN "clazzes" ON "clazzes"."id" = "teacherships"."clazz_id" INNER JOIN "schools" ON "schools"."id" = "clazzes"."school_id" WHERE "clazzes"."name" = "1班" AND "groups"."name" = "A组" AND "schools"."name" = "第一中学"
附上一份各种JOIN的差异对比,帮助我自己记忆:P
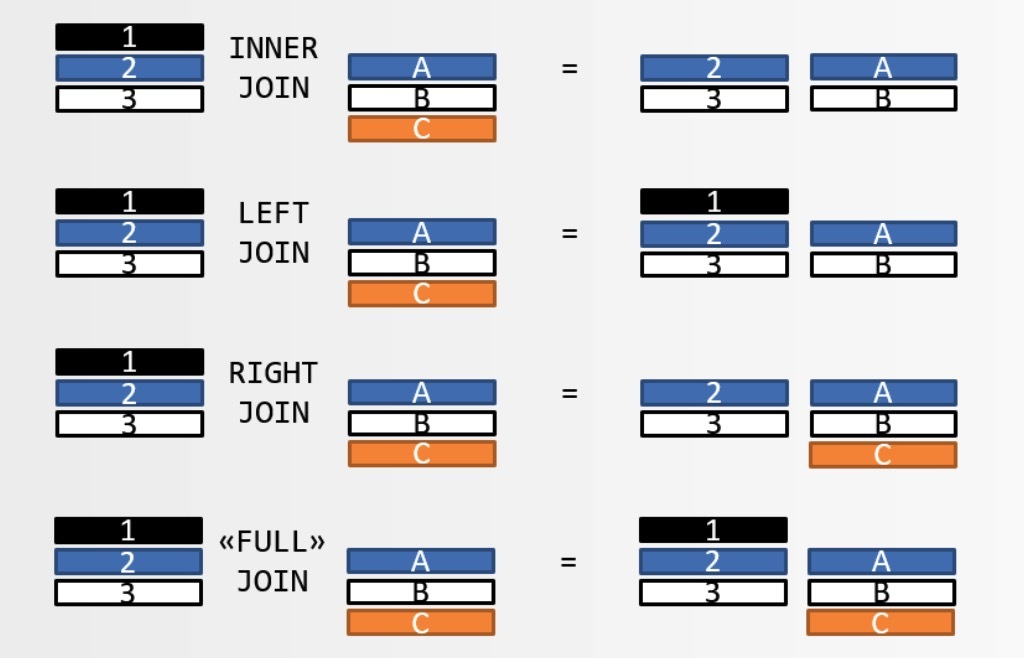
图片来源: say no to venn digrams when explaining joins
includes
N+1效能查询的解决方法。
clazzes = Clazz.includes(:school).limit(10)
对应的SQL:
SELECT "clazzes".* FROM "clazzes" LIMIT 10
SELECT "schools".* FROM "schools"
WHERE "schools"."id" IN (617,1604,783,2554,1841,1469,446,2820,1566,2741)
这里先找到10个clazz,然后根据这10个clazz查找对应的school, 有重复的school_id则去重复查询。
类似joins,includes也可以关联多表:
Clazz.includes(:school, :orders).limit(10)
对应的SQL:
SELECT "clazzes".* FROM "clazzes" LIMIT 10
SELECT "schools".* FROM "schools" WHERE "schools"."id" IN (617,1604,783,2554,1841,1469,446,2820,1566,2741)
SELECT "orders".* FROM "orders" WHERE "orders"."clazz_id" IN (4732,1648,3715,963,278,4525,7096,9064,10299,7980)
嵌套includes:
Clazz.includes(:school, orders: [:product]).limit(10)
对应的SQL:
SELECT "clazzes".* FROM "clazzes" LIMIT 10
SELECT "schools".* FROM "schools" WHERE "schools"."id" IN (2741,2742,2743,2744)
SELECT "orders".* FROM "orders" WHERE "orders"."clazz_id" IN (4732,1648,3715,963,278,4525,7096,9064,10299,7980)
SELECT "products".* FROM "products" WHERE "products"."id" IN (7,4,16)
nested部分,根据clazz的ID,找到对应的order,然后根据order的ID,再找到product,这里可以看成有一层Order.includes(:product)。
通过explain方法可以很清楚看到SQL的查询步骤【后面会提到】
上述nested includes,对应的SQL查询步骤:
=> EXPLAIN for: SELECT "clazzes".* FROM "clazzes" LIMIT $1 [["LIMIT", 10]]
QUERY PLAN
-------------------------------------------------------------------
Limit (cost=0.00..0.42 rows=10 width=99)
-> Seq Scan on clazzes (cost=0.00..399.53 rows=9553 width=99)
(2 rows)
EXPLAIN for: SELECT "schools".* FROM "schools" WHERE "schools"."id" IN ($1, $2, $3, $4, $5, $6, $7, $8, $9, $10) [["id", 617], ["id", 1604], ["id", 783], ["id", 2554], ["id", 1841], ["id", 1469], ["id", 446], ["id", 2820], ["id", 1566], ["id", 2741]]
QUERY PLAN
--------------------------------------------------------------------------------------
Seq Scan on schools (cost=0.00..40.53 rows=10 width=141)
Filter: (id = ANY ('{617,1604,783,2554,1841,1469,446,2820,1566,2741}'::integer[]))
(2 rows)
EXPLAIN for: SELECT "orders".* FROM "orders" WHERE "orders"."clazz_id" IN ($1, $2, $3, $4, $5, $6, $7, $8, $9, $10) [["clazz_id", 4732], ["clazz_id", 1648], ["clazz_id", 3715], ["clazz_id", 963], ["clazz_id", 278], ["clazz_id", 4525], ["clazz_id", 7096], ["clazz_id", 9064], ["clazz_id", 10299], ["clazz_id", 7980]]
QUERY PLAN
--------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on orders (cost=47.22..1262.09 rows=392 width=194)
Recheck Cond: (clazz_id = ANY ('{4732,1648,3715,963,278,4525,7096,9064,10299,7980}'::integer[]))
-> Bitmap Index Scan on index_orders_on_clazz_id (cost=0.00..47.12 rows=392 width=0)
Index Cond: (clazz_id = ANY ('{4732,1648,3715,963,278,4525,7096,9064,10299,7980}'::integer[]))
(4 rows)
EXPLAIN for: SELECT "products".* FROM "products" WHERE "products"."id" IN ($1, $2, $3) [["id", 7], ["id", 4], ["id", 16]]
QUERY PLAN
----------------------------------------------------------
Seq Scan on products (cost=0.00..1.62 rows=3 width=391)
Filter: (id = ANY ('{7,4,16}'::integer[]))
(2 rows)
includes后,如果添加where条件,则需要传递一个hash给到where,如果不是hash,则需要使用references强制连接table。
比如:
Clazz.includes(:school).where("schools.name ='第一小学'").references(:schools)
## 等同于
Clazz.includes(:school).where(schools: { name: "第一小学"})
注意到includes接受的参数同joins,是association names,而references则是表名。
counter_cache
用来快速获取关联计数,假设school model中有teachers_count这个字段,那么:
class Teacher < ApplicationRecord
belongs_to :school, :counter_cache => true
end
这样ActiveRecord就会自动更新schools中的teachers_count的值。
这里counter_cache对应的列名可以自定义,比如说老师和学生之间是一对多的关系,给老师这张表添加一个字段total_students_count ,则可以在student的model中这么设置:
class Student < ApplicationRecord
belongs_to :teacher, counter_cache: "total_students_count"
end
find_each
find_each 分批查询, 默认每次捞出1000条记录。
有三个参数可以设置:
- batch_size
- start
- finish
batch_size
指定每次捞出的数据量。
School.find_each(batch_size: 200) do
end
那么每次则捞出200条记录,对应到SQL中,则是limit的值变成了200。
默认是按照primary key(id) 升序排序查询结果:
SELECT "schools".* FROM "schools" ORDER BY "schools"."id" ASC LIMIT 200
SELECT "schools".* FROM "schools" WHERE "schools"."id" > 200 ORDER BY "schools"."id" ASC LIMIT 200
……
start
从哪条记录开始查询, 默认参数是ID。
比如:
School.find_each(start: 200) do
end
对应的SQL:
SELECT "schools".* FROM "schools" WHERE "schools"."id" >= 200 ORDER BY "schools"."id" ASC LIMIT 1000
finish
指定到哪条记录截止, 默认参数是ID。
比如:
School.find_each(finish: 2000) do
end
对应的SQL:
SELECT "schools".* FROM "schools" WHERE "schools"."id" <= 2000 ORDER BY "schools"."id" ASC LIMIT 1000
start搭配finish:
School.find_each(start: 200, finish: 2000) do
end
对应的SQL:
SELECT "schools".* FROM "schools" WHERE "schools"."id" >= 200 AND "schools"."id" <= 2000 ORDER BY "schools"."id" ASC LIMIT 1000
explain方法
可以用来查看SQL的执行步骤。rails c进入console,执行:User.where(id: 1).explain, 会得到如下结果:
=> EXPLAIN for: SELECT "users".* FROM "users" WHERE "users"."id" = $1 [["id", 1]]
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using users_pkey on users (cost=0.42..8.44 rows=1 width=387)
Index Cond: (id = 1)
(2 rows)
显示了数据查询的过程,扫描users的index,最后找到id为1的user。
看一个joins的例子:
Teacher.joins(:clazzes, :groups).explain
对应的输出:
=> EXPLAIN for: SELECT "teachers".* FROM "teachers" INNER JOIN "clazzes" ON "clazzes"."id" = "teachers"."clazz_id" INNER JOIN "groups" ON "groups"."teacher_id" = "teachers"."id"
QUERY PLAN
------------------------------------------------------------------------------------------
Nested Loop (cost=0.99..2382.37 rows=1 width=387)
-> Nested Loop (cost=0.71..2382.05 rows=1 width=391)
-> Seq Scan on groups (cost=0.00..6.02 rows=302 width=4)
-> Index Scan using teachers_pkey on teachers (cost=0.42..7.86 rows=1 width=387)
Index Cond: (id = groups.teacher_id)
-> Index Only Scan using clazzes_pkey on clazzes (cost=0.29..0.33 rows=1 width=4)
Index Cond: (id = teacherships.clazz_id)
(7 rows)
看一个includes的例子,多表includes:
Clazz.includes(:school, :groups).limit(10).explain
对应的输出:
=> EXPLAIN for: SELECT "clazzes".* FROM "clazzes" LIMIT $1 [["LIMIT", 10]]
QUERY PLAN
-------------------------------------------------------------------
Limit (cost=0.00..0.42 rows=10 width=99)
-> Seq Scan on clazzes (cost=0.00..399.53 rows=9553 width=99)
(2 rows)
EXPLAIN for: SELECT "schools".* FROM "schools" WHERE "schools"."id" IN ($1, $2, $3, $4, $5, $6, $7, $8, $9, $10) [["id", 617], ["id", 1604], ["id", 783], ["id", 2554], ["id", 1841], ["id", 1469], ["id", 446], ["id", 2820], ["id", 1566], ["id", 2741]]
QUERY PLAN
--------------------------------------------------------------------------------------
Seq Scan on schools (cost=0.00..40.53 rows=10 width=141)
Filter: (id = ANY ('{617,1604,783,2554,1841,1469,446,2820,1566,2741}'::integer[]))
(2 rows)
EXPLAIN for: SELECT "groups".* FROM "groups" WHERE "groups"."clazz_id" IN ($1, $2, $3, $4, $5, $6, $7, $8, $9, $10) [["clazz_id", 4732], ["clazz_id", 1648], ["clazz_id", 3715], ["clazz_id", 963], ["clazz_id", 278], ["clazz_id", 4525], ["clazz_id", 7096], ["clazz_id", 9064], ["clazz_id", 10299], ["clazz_id", 7980]]
QUERY PLAN
----------------------------------------------------------------------------------------------
Seq Scan on groups (cost=0.00..9.79 rows=14 width=36)
Filter: (clazz_id = ANY ('{4732,1648,3715,963,278,4525,7096,9064,10299,7980}'::integer[]))
(2 rows)
可以很清楚地看到分开两步,查询到clazz对应的ID后,分别查询了schools和groups,呃,不多说了,太明显了。