《Ruby元编程》之对象模型笔记。
写在前面
看完了Ruby元编程(第2版),全书三大part,共13章,第一部分Ruby元编程是重点,也是基础,理解了part 1, part 2的Rails元编程也就七七八八了,part 3是附录,供延伸阅读。
part 1读起来让人有种醍醐灌顶之感,很是惊喜,part 2告诉了你rails源代码中一些故事,针对这两块简单做了些笔记,打算整理出来,加深理解,也顺带梳理一下Ruby的知识点。
这篇来写写Ruby中的对象,类及方法调用。
对象
对象是由一组实例变量和对自身类的引用构成。
实例变量
看个书中的例子:
class MyClass def my_method @v = 1 end end object = MyClass.new # 这时object.instance_variables是[] object.my_method # 这时object.instance_variables是@v这里,@v是实例变量,object 创建时,并没有任何实例变量,当object调用my_method时,它有了实例变量@v。你可以通过
object.instance_variables来验证。
方法
通过
object.methods可以得到对象object的所有方法,这些都是MyClass类的实例方法。方法存放在类中,而不是对象中,实例变量则存放在对象中。也就是同一个类的对象共享同样的方法,但不共享实例变量。
类
类是一个对象(Class类的一个实例)加一组实例方法和一个对其超类(superclass)的引用。
类本身也是对象,它是Class的一个实例。Class.class是Class。
Class.superclass是Module,因此一个类也是一个模块。
在一些静态语言中,比如Java,实例是类的一个不可修改的对象,但是Ruby允许你打开修改, 这种操作又称之为打开类。
可使用class_eval method来打开任意类。
打开类(open class)与猴子补丁(monkey patch)
看个简单的例子:
class A def a; 'a'; end end class A def b; 'b'; end end obj = A.new obj.a obj.b这里,Ruby先是定义了这个类A,并定义了method a,随后,Ruby重新打开了类A,定义了method b。
打开类是Ruby很强大的利器,可以动态修改已经存在的类,即使是String,Array这类标准库中的类也不例外。
不过利剑用的不好,容易伤着自己。打开类容易带来猴子补丁的问题。
书中举的例子很好,这里直接引用:
class Array def replace(original, replacement) self.map {|e| e == original ? replacement : e} end end这里,打开了Array这个标准库中的类,然后定义了一个replace的method,我们知道Array自身已经有一个replace的method了,那么重新定义,会覆盖掉原来的replace,而你的程序中的其他部分极有可能依赖于原来的replace,这可能会导致危险的后果。这种method就属于猴子补丁。
如何解决?
两种方法。
换个名字
比如replace换成substitute,同时仔细检查该类中是否有同名的方法,确保新的名字不存在monkey patch的情况。
用细化(Refinement)
先定义一个module,然后在这个module里面定义这个method,然后使用using方法来启用这个method,细化的作用范围只在声明了using的模块内部有效。看例子:
module ArrayExtensions refine Array do def replace(original, replacement) self.map {|e| e == original ? replacement : e} end end end module ArrayStuff using ArrayExtensions ["a", "b", "c"].replace("a", "d") # => ["d", "b", "c"] end ["a", "b", "c"].replace(["a", "d"]) # => ["a", "d"]前者调用的是在ArrayExtensions中refine的method replace,而且只在声明了using ArrayExtensions的module ArrayStuff有效, 后者调用的则是Array标准库中的replace method。
它只在你希望它生效的地方生效,这真的蛮好。不过细化也有其陷阱,看段代码:
class MyClass def my_method puts "original my_method" end def my_other_method my_method end end module MyClassRefinement refine MyClass do def my_method puts "refined my_method" end end end using MyClassRefinement MyClass.new.my_method # => "refined my_method" MyClass.new.my_other_method # => "original my_method"这里,my_other_method对my_method的调用,是在using之后,所以后面还是调用了之前未细化的my_method,所以用细化的时候还是要小心些。
Superclass
superclass是一个类方法,可以获取当前类的父类。像上面细化例子里面的MyClass,它的superclass是Object。
Array.superclass # => Object Object.superclass # => BasicObject BasicObject.superclass # => nil以MyClass为例,obj是它的实例对象,对应的class, superclass如下:
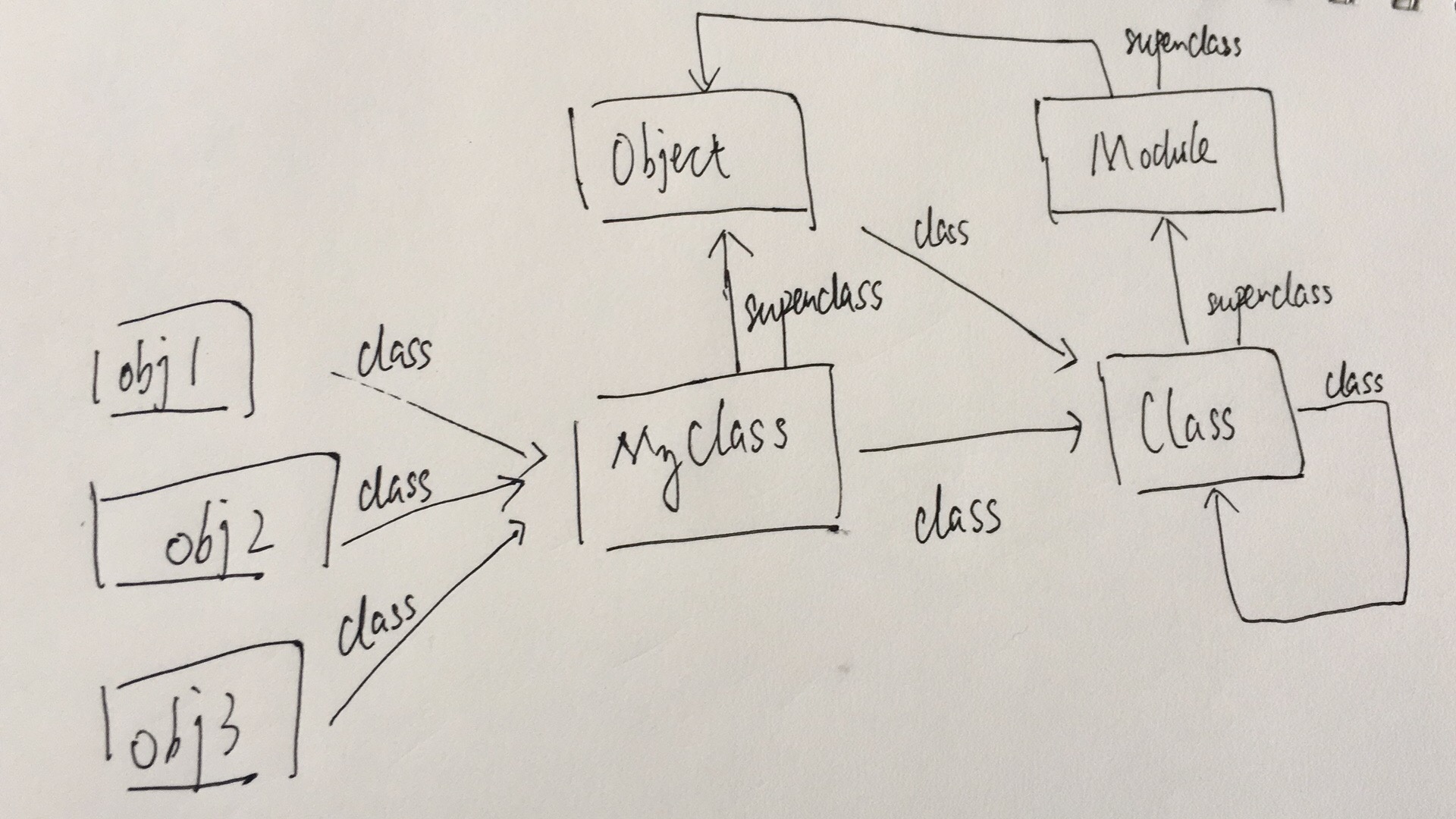
模块Module
Class.superclass => ModuleModule可以看成是一堆method的集合,类和模块很接近,使用的时候,如果你希望自己的代码包含在别的代码中,使用module,如果希望某段代码被实例化或者被继承,用类。
常量
任何以大写字母开头的引用都是常量,包括类名和模块名。
Ruby中的常量类似变量,它的值是可以修改的,那么它与变量有什么区别?最大的区别在于作用域。
Ruby代码中的常量类似于文件系统中的文件,类和模块就像是目录。类似不同目录下,不同文件可以有相同的名字,不同的模块和类中,也可以有相同名字的常量。
看个例子:
module M MyContant = 'outer contant' class C MyContant = 'inner contant' end C::MyContant # => "inner contant" M::MyContant # => "outer contant" end M::C::MyContant # => "inner contant"这里,常量使用了路径引用的方式。用::进行分割。而M这种用来充当常量容器的模块,被称之为命名空间。
命名空间
我觉得命名空间的一个作用是隔离。比如下面这种:
module N class C puts "in module N" end end module M class C puts "in module M" end end N::C # => in module N M::C # => in module M使用命名空间可以轻松解决类同名的问题。这里书中提到了一个细节,有关load的使用。
load用于加载代码,比如
load('demo.rb'),demo.rb文件中如果定义了常量,就有可能污染当前程序的命名空间,怎么解决?通过参数来强制限定其只在自身范围内有效:load('demo.rb', true).
方法的调用
方法的调用分为方法的查找和执行。
在细说之前,先说两个概念:接受者,祖先链
接收者:调用方法所在的对象,比如my_array.replace(), 这里my_array就是接收者。
祖先链:以任意一个Ruby类为例,它从superclass一路往上找,superclass的superclass,直到BasicObject,其经历的路径,就是该类的祖先链。
查看某个class的祖先链,使用ancestors【这是一个类方法】。比如:
Array.ancestors # => [Array, Enumerable, Object, Kernel, BasicObject]
这里Kernel模块是包含在Object这个class中的。于是,无论哪个对象都可以随意使用Kernel模块中的方法,这些方法又称之为内核方法(Kernel Method).同样,你也可以打开Kernal,新增方法,这个方法就会对所有的对象可用了,cool吧?
祖先链中包含模块,当某个模块包含在某个类中时,Ruby就会把该模块加入到祖先链中。
模块的位置在include它的类之上。如果是prepend, 则是在prepend它的类之下。
【prepend也是很好的方法包装术,后面的章节中它还会出场】
看几个例子加深理解:
module M1; end
class C
include M1
end
class D < C; end
D.ancestors # => [D, C, M1, Object, Kernel, BasicObject]
class C2
prepend M1
end
class D2 < C2; end
D2.ancestors # => [D2, M1, C2, Object, Kernel, BasicObject]
一个模块只会在祖先链中出现一次:
module M1; end
module M2
include M1
end
module M3
prepend M1
include M2
end
M3.ancestors # => [M1, M3, M2]
人生的出场顺序很重要,祖先链中也是:
module M1; end
module M2; end
class C
include M1
include M2
end
class C2
include M2
include M1
end
C.ancestors # => [C, M2, M1]
C2.ancestors # => [C2, M1, M2]
理解祖先链很有必要,它对于理解后面章节中,特别是单件类,类方法,实例方法等的覆写,扩展等很有帮助。
方法查找
一句话:向右一步,再向上
搞懂了祖先链,其实也就知道了方法的查找,从接收者对应的class开始(向右一步),一直沿着祖先链往上找,直到找到这个method即可。
看个例子:
module M1 def hello puts "hello, Ruby! this is M1" end end module M2 def hello puts "hello, Ruby! this is M2" end end class C include M1 include M2 end C.new.hello这里hello是调用哪个?
我们知道C.ancestors是 [C, M2, M1],M2中有hello这个method,所以它会找到最近的那个,也就是M2的hello ,输出:
hello, Ruby! this is M2。方法执行
Ruby中每一行代码都会在一个对象中被执行,这个对象就是所谓的当前对象,可以用self表示。
任何时刻,只有一个对象可以充当当前对象,当调用一个方法时,接收者就成为了self。
看个例子【书中的这个例子很好,直接拿来】:
class C def test_self @var = 1 my_method() self end def my_method @var = @var + 1 end end obj = C.new obj.test_self # => #<C:0x007faf9d0588f0 @var=2>调用test_self时,obj就成为了self,@var成了obj的实例变量,执行my_method时,@var仍然是obj的实例变量, 最后返回self的引用,可以看到@var变为2。
有关self部分,可以顺带说说两种情况。
顶层上下文(top level context)
如果没有调用任何方法,此时谁是self?运行irb,问Ruby:
self # => main self.class # => ObjectRuby程序开始运行时,解释器会创建一个名为main的对象作为当前对象,也就是self。这个对象又叫做顶层上下文(top level context)。
类或模块中,self的角色由这个类或模块本身担任
书中还提到了借助self,重新理解private。即:不能明确指定接收者来调用私有方法。
看个例子:
class C def public_method self.private_method end private def private_method; end end end C.new.public_method运行时会报错:
private method `private_method' called for #<C:0x007fce270f4478> (NoMethodError)因为此处用了self,所以调用public_method时,C的对象便成为了self, 而private_method是不能直接被实例对象调用的。去掉public_method中的self即可。
这部分的主要内容基本如上,是不是感觉学到了好多?: P
结尾
去年打开《Ruby元编程》的时候,看得云里雾里,无法继续,现在再次打开,却有种拨开云雾之感,好似你懂了你曾不懂的,不知如何准确描述这种欣喜的感觉。Whatever,I love it!
推荐这本Ruby元编程(第2版)