这是 IPFS 相关内容的第一篇, 打算花点时间把之前自己刷 ProtoSchool 系列课程所学到的知识梳理下.
第一篇就从 CID 开始吧.
当然, 又一次, 强烈推荐刷原文 ,妥妥真香系列.
是什么与为什么
CID 是 Content Identifier 的缩写, 中文可以译成内容标识符.
CID是用来做什么的呢?
我们知道, 网络中用于标识资源的方式是统一资源标识符URI(Uniform Resource Identifier).
URI主要有两种类型: URL(Uniform Resource Locator) 和 URN( Uniform Resource Name).
在Web2.0中, 我们最常用的是URL. 即统一资源定位符, 资源基于数据存储的位置来寻址. 这种标识资源的方式, 可以称之为 Location addressing.
比如一张图片的URL 为https://www.puppies.com/cute_cat.jpg .我们会预设, 这是一个有关小猫照片的URL. 访问该URL后, 会看到一张猫咪的萌照.
那么URLs这种标识资源的方式会有什么问题呢?
最主要的就是安全问题.
我们无法通过一个URL, 来验证这个URL给到我们的是我们想要的内容. 比如上面的URL, 可能打开后, 不是一张猫咪的萌照, 而是一张小狗的照片, 甚至可能会是一个木马病毒.
也就是说, 托管在中心化网络上的文件, 它们的内容与它们基于位置的地址 URLs 是没有直接关系的. 我们不能通过URLs或者文件名来确定资源的内容.
另一个存在的问题是大量重复的资源文件存储在相同或者不同的服务器上. 用户看到的是不同的URLs, 但这些URLs 所标识的都是完全一样的资源文件, 这就造成空间上不必要的浪费.
那么, 能否有一种基于文件内容的标识符呢? 我们能否从 location-based addressing 转向 content-based addressing?
答案当然是Yes : P
在去中心化的网络中, 资源的标识就是基于内容的.
针对任意给定的资源文件, 我们可以通过特定的算法, 为其生成唯一的识别码. 即Content addressing.
这里要介绍的CID, 就是一种特殊形式的内容寻址.
这种基于内容的资源标识方式, 相比URLs, 除了更安全, 避免资源冗余外, 还有一个优势.
在中心化的网络中, 当我们基于某个URLs去获取数据时, 如果该服务点挂了, 那我们就无法获取到数据了, 但是在去中心化的网络中, 我们只要有所需要资源的内容地址, 比如CID, 就可以向全网的节点发送请求.
了解了是什么和为什么后, 我们来看看CID具体是怎么生成的.
基本构成及演进
CID 由IPFS 开发. 一个常见的CID 长这样:
QmY7Yh4UquoXHLPFXbhXkhBvFoPwmQUSa92pxnxjQuPU |
CID的大致创建过程, 是使用一种加密算法(cryptographic algorithm),将任意大小的输入(数据或文件)映射到固定大小的输出。这种对于输入数据的转换, 称为加密哈希摘要(cryptographic hash digest)。
IPFS目前大部分CID是使用 sha2-256 算法, 也就是 256 bits, 32bytes.
从这里也可以看出, CID的长度, 是由 cryptographic hash 加密哈希算法来决定的, 而跟文件本身的大小无关. 任意长度的输入通过相同的哈希函数进行处理, 会得到固定长度的输出.
但鉴于哈希算法可能会被证明是不安全的, 比如 sha1 , 所以CID需要支持多种哈希算法.
既然要支持多种加密算法,那我们怎么知道这个特定的哈希值是使用哪种算法生成的呢?
CID 使用 multihash 来标识所用的加密算法.
具体就是将长度和使用的算法, 作为Hash值的唯一识别前缀.
Multihash
Multihash 遵循 TLV 模式, 即 Type, Length, Value:

Type
标识所使用的加密算法 cryptographic algorithm.
通过 multicodec table 可以查看对应的算法, 比如,
sha2-256的code 为 18, 用16进制表示则是0x12
Length
长度, 如果用的是
sha2-256算法, 则是32 bytes
Value
生成的哈希值
当我们通过加密哈希摘要得到一个固定大小的输出时, 这个输出是二进制格式的. 对受众来说, 不是那么友好, 因此需要将其编码成字符串, 用字符串表示CID.
IPFS 最初是使用 base58btc 将二进制格式的哈希值, 进行编码压缩, 得到类似这样的结果:
QmY7Yh4UquoXHLPFXbhXkhBvFoPwmQUSa92pxnxjQuPU |
以 Qm开头, 这也就是第一代CID v0.
但随之问题也就来了.
我们如何得知程序是用什么方法对原数据本身进行了编码? 我们知道文件内保存数据的形式是二进制, 将二进制数据序列化用的是 protobuf 还是JSON, 抑或是其他 ?
我们如何得知程序是用什么方法来创建CID的字符串表示的? CIDv0 版本使用了 base58btc , 但是如果我们想要使用 base32 或者 base64 怎么办呢?
为了解决这两个问题, CID不得不演进, 由此, CIDv1应运而生.
针对第一个问题, CIDv1 引入了另外的前缀, 用来标识针对文件数据所使用的编码方式. 也就是 Multicodec Prefix.
这样, 我们的CID 就扩展成了这样:

这里 Multicodec Prefix 的值是 01110000, 即 0x70, 查看codec identifier table, 对应的就是 dag-pb.
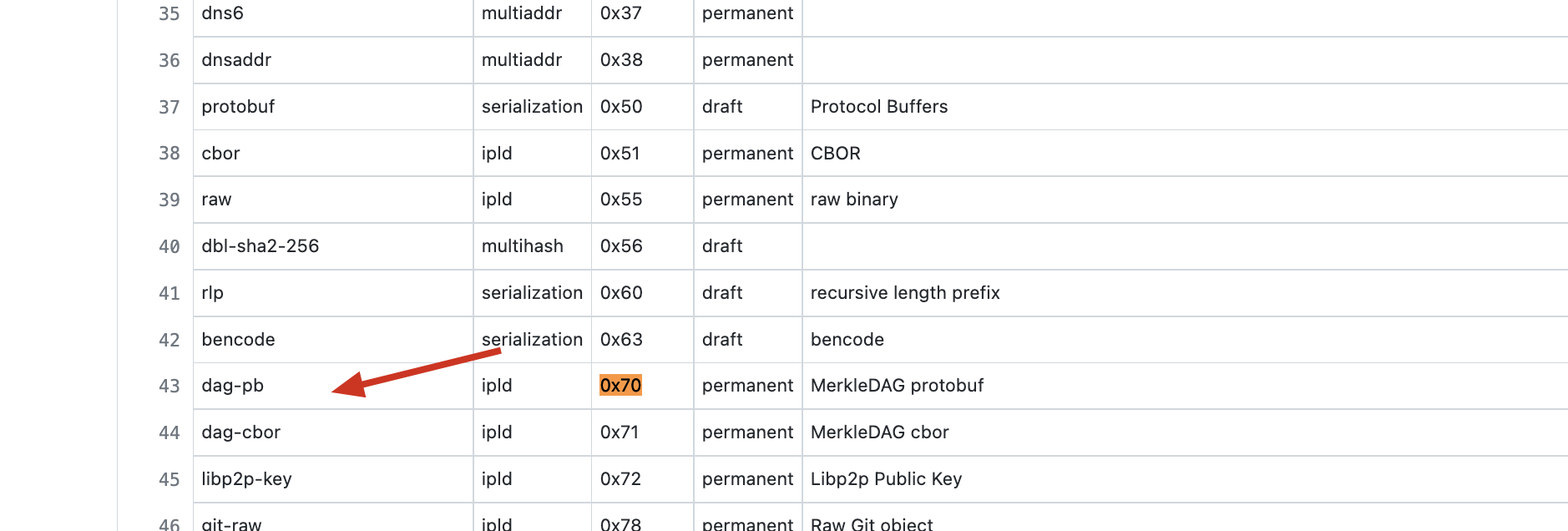
dag-pb 表示 MerkleDAG protobuf, 是 IPLD (InterPlanetary Linked Data)的一种. [不懂 IPLD? 没事, 我暂时也没整明白, 先把 dag-pb 当作是一种特殊的 protobuf 看待, 不影响整体理解]
为了区分版本, CIDv1 还添加了 version prefix.
所以整个 CID 的构成就变成这样:
<cid-version><multicodec><multihash-algorithm><multihash-length><multihash-hash> |
其中, cid-version 表示CID的版本.

针对第二个问题, 我们已经知道, CIDv0 中, 默认使用base58btc.
那么在CIDv1及之后的版本中, 如果我们使用了其他的编码方式, 如何让他人知道你使用的是哪种编码方法呢?
大概你也猜到了, 继续用前缀. [不得不叹一句: 前缀大法好]
Multibase prefix 就是用来表示在字符串和二进制格式之间转换CID时所使用的基础编码。
与前面Multicodec prefix 不同的是, 它不是放在二进制格式的输出结果中, 而是放在了转换后的字符串中.

来看两个字符串格式的CID:
QmbWqxBEKC3P8tqsKc98xmWNzrzDtRLMiMPL8wBuTGsMnR |
我们知道第一个CID是CIDv0, 因为它以Qm开头, 第二个以b开头, 表示编码方法为 base32.
通过查看完整的 multibase 表, 可以知道CID具体所采用的基础编码方法.
至此, 我们基本把CID的构成和演进理得差不多了.
如果你本地安装了ipfs, 通过命令行, 可以查看CID 的相关内容, 比如支持的base encoding:
ipfs cid bases |
支持的 Cryptographic hashing 算法:
ipfs cid hashes |
目前ipfs (0.11.0) 的CID, 依然默认是 v0 版本.
在线解析
考虑到CID的构成复杂, IPFS提供了CID inspector 来帮助我们解析CID结果.
以 QmbWqxBEKC3P8tqsKc98xmWNzrzDtRLMiMPL8wBuTGsMnR 为例:
结果如下:
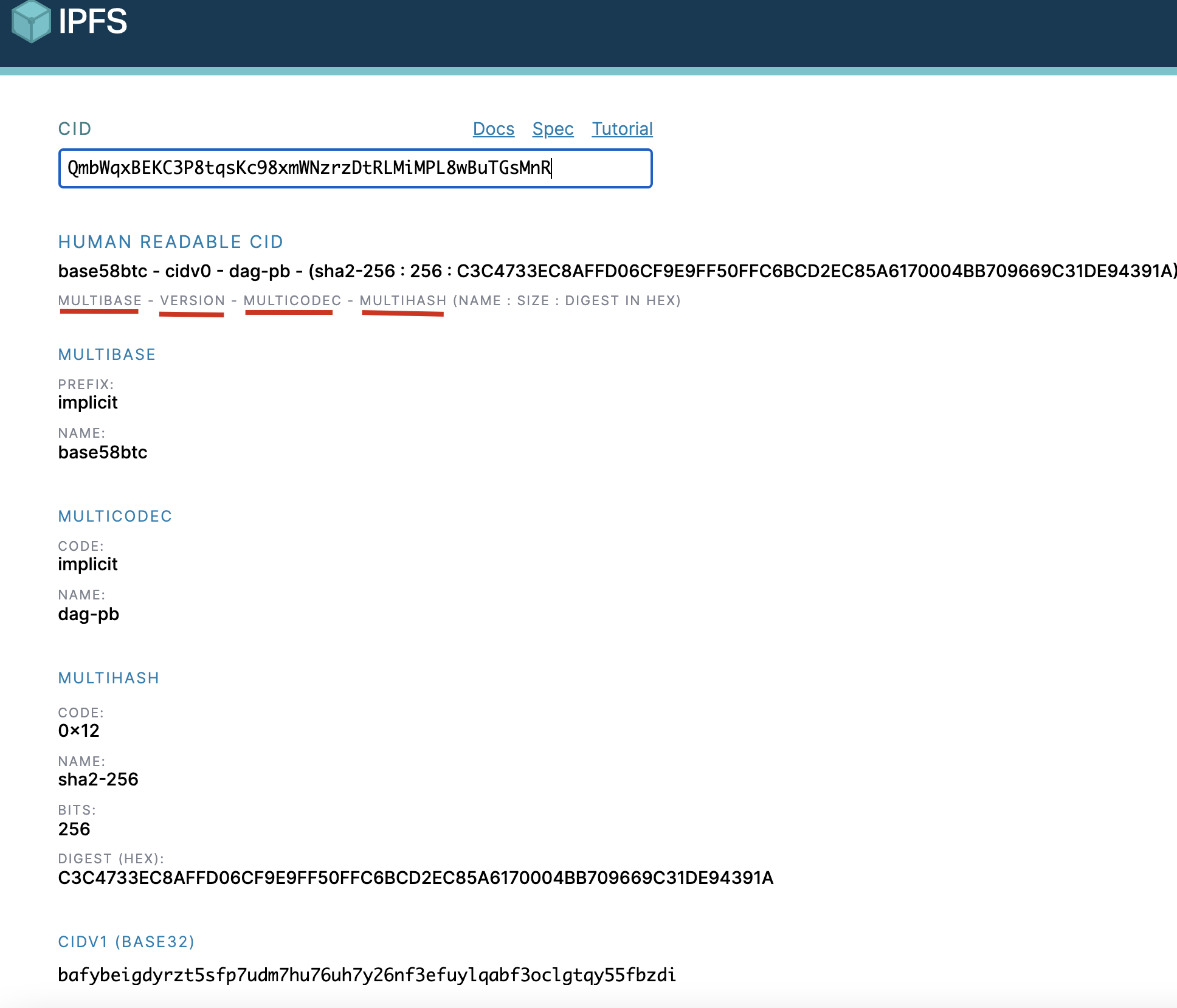
这里我们可以分别看到 multibase, version, muticodec, multihash对应的值.
稍稍提一下, 因为 multibase和 muticodec 是CIDv1后提出的, 而我们的CID 是v0版本的, 所以解析后, 这两部分显示了 implicit.
我们将解析后得到的CIDv1, 继续解析, 得到如下的结果:
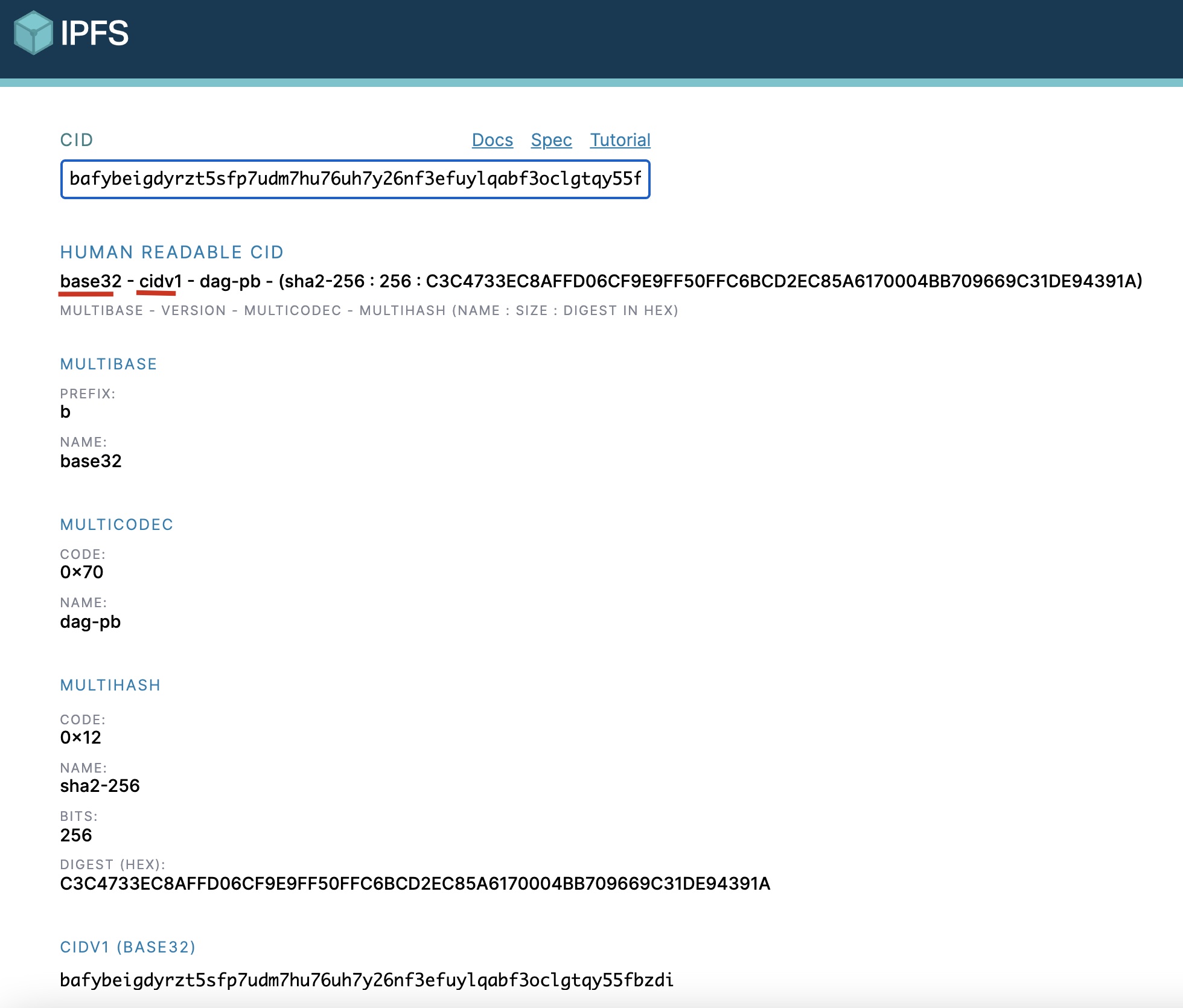
此时, 我们看到multibase 为base32.
不管是 v0 还是 v1 的CID, 它们的摘要值都是C3C4…31DE94391A, 表示着同一份文件.
OK, 基本算是缕得差不多了, CID的内容就先到这啦.